雷鋒網按:本文原作者MagicBubble,原載于知乎專欄人工智障的深度瞎學之路。雷鋒網已獲得作者授權。
利用一個暑假的時間,做了研究生生涯中的第一個正式比賽,最終排名第二,有些小遺憾,但收獲更多的是成長和經驗。我們之前沒有參加過機器學習和文本相關的比賽,只是學過一些理論基礎知識,沒有付諸過實踐,看過的幾篇論文也多虧前輩的分享(一個是用深度學習(CNN RNN Attention)解決大規模文本分類問題 - 綜述和實踐,另一個是 brightmart 的 text_classification,里面用 Keras 實現了很多文本分類的模型)。這些為我們的入門打下了良好的基礎,在比賽過程中也是反復研讀和實踐,在此感謝兩位前輩的無私分享。
先放一波鏈接:
下面對在這次比賽中用到的方法和收獲的經驗,做一個簡單的總結和分享。
用單模型探索數據的極限
1. 任務
典型的文本多標簽分類問題,根據用戶在知乎上發布的問題標題及描述,判斷它屬于哪幾個話題
訓練數據給出了 300 萬問題及其話題的綁定關系,話題標簽共有 1999 個,有父子關系,構成有向無環圖
要求對未標注的數據預測其最有可能綁定的 Top5 話題標簽
評測采用準確率與召回率的調和平均,準確率的計算按照位置加權,越靠前的分數越高(具體見評測方案)
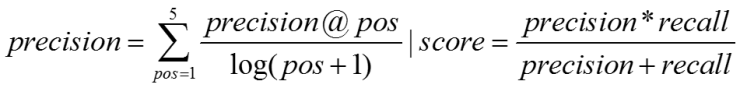
2. 數據
比賽提供的數據是 300 萬問題和話題的標題(下稱 title)及描述(下稱 desc),分別有對應的字序列(下稱 char)和詞序列(下稱 word),全部是以 id 的形式給出。這意味著我們是看不到原始文本的,所以對于 badcase 的分析也很困難,但好在其數據量夠大(2 億多詞,4 億多字),還是可以用深度學習來做。知乎官方也提供了訓練好的 embedding(維度 256),字級別和詞級別的都有,但是是分開訓練,不屬于同一個語義向量空間。

坊間常說:數據和特征決定了機器學習的上限,而模型和算法知識逼近這個上限而已。對于深度學習,因為不存在特征工程,所以數據處理就至關重要了。而良好且合理的數據處理離不開系統詳細的數據分析,要知道數據是什么樣,數據怎么分布,才能更好地選擇模型和訓練方式。
2.1 數據分析
這里主要是對問題的 title 和 desc 做長度分析,更為詳細的分析見數據分析
首先是問題 title 的字詞長度分布:

其次是問題 desc 的字詞長度分布:

2.2 預處理
隨機 shuffle 后以 9:1 的比例劃分線下驗證集和訓練集,防止數據周期的影響
對于 embedding 矩陣中未出現的詞,添加,并用 - 0.25~0.25 初始化,千萬不能扔掉,這樣會破壞前后的語義關系
對于 title 和 desc,分別根據其平均長度 * 2,做截斷和補齊至長度一致,便于 batch 輸入網絡訓練

3. 模型
參照 brightmart 的 github 開源,我們嘗試了前 5 種模型,分別是 FastText、TextCNN、TextRNN、RCNN、HAN
其中,HAN 的原始論文中用的是詞和句子兩層 Attention,而數據中是看不出句子的,所以這個方法我只用了一層 word,效果不好。而 RCNN 因為同時用到了 RNN 和 CNN 的思想,所以整個網絡的訓練時間很長,且其效果與單獨的 RNN 和 CNN 差不多,因此后期沒有使用此模型。最終用到的模型有:

3.1 單模型 Score
因為沒有花很多時間在單模型調參訓練上,所以最終單 Model 的分數普遍偏低,約比別的隊伍低 0.5~1 個百分點。

3.2 核心思路
這是我們這次參賽的一大亮點和創新點,就是成功地在深度學習上應用了一種類似于 AdaBoost 的做法,通過訓練多層來不斷修復前面層的偏差。我們在分析數據的時候發現,一個模型的輸出是具有類別傾向性的,所以在某些類別上可能全對,而在某些類別上可能全錯,所以我們針對這種偏差做了一些改進,通過人為地定義偏差的計算方式,指導下一層模型更多關注那些錯的多的類,從而達到整體效果的提升。

通過用這種方法,單模型 Score 有了質的飛躍,平均提升都在 1.5 個百分點(FastText 因模型過于簡單,提升空間有限),而 10 層的 RNN 則更是在用全部訓練集 finetune 之后,分數直接從 0.413 飆升到 0.42978,可謂真是用單模型探索數據的極限了。

這種方法的優勢在于,一般只要不斷加深訓練層數,效果就會提升,但缺點卻在于它抹平了模型的差異性,對于模型融合效果不友好。
3.3 模型融合
模型融合依靠差異性,而我們模型的差異性在前面已經近乎被抹平,所以又另尋他路,用了另外兩個方法:
最終模型主要是 5 個 10 層模型的概率加權融合,分數在 0.43506。
4. 結束語
這次比賽收獲很大,總結起來就是:
最后,還是要感謝知乎等組織舉辦的這次比賽,也感謝北郵模式識別實驗室的大力支持!
雷峰網版權文章,未經授權禁止轉載。詳情見轉載須知。





